Questions of Linux Art
进程2(Shell)
为何要提前打开stdio文件,然后再关闭
IA32 Assembly
| |
Homework Questions
注意Linux-0.11只支持单核,没有那么多并发和内核锁的需求
请结合书内容阅读
第二次作业
问题
- 为什么开始启动计算机的时候,执行的是BIOS代码而不是操作系统自身的代码?
Answer: 刚启动计算机的时候内存里没有任何合法数据,需要从BIOS芯片开始执行,从磁盘搬运操作系统代码到内存之后才可以执行。
问题
- 为什么BIOS只加载了一个扇区,后续扇区却是由
bootsect代码加载?为什么BIOS没有直接把所有需要加载的扇区都加载?
Answer: 不同操作系统的实现是不同的,bootsect之外的代码大小和位置都不容易确定,因此主板BIOS和操作系统遵循统一设计约定,只将最多一个扇区(512B)的bootsect放在起始位置,BIOS仅负责加载bootsect,剩下的操作系统内核程序由bootsect自行/自由加载
问题
- 为什么BIOS把
bootsect加载到0x07c00,而不是0x00000?加载后又马上挪到0x90000处,是何道理?为什么不一次加载到位?
Answer:
- 内存起始处已经设置了中断向量表,将
bootsect加载到0x0会引起冲突; - 操作系统可以自由决定内存布局,原先BIOS所在的
0x7c00处将会有其他的数据结构占用,需要移往更高的安全地址,Linux选取的是0x90000; - 不一次加载到
0x90000处是因为BIOS设计者向前兼容了内存只有640KB或更少内存的旧设备,将BIOS的寻址空间作了限制,而两段加载的方式给予操作系统设计者更加自由的内存安排选择。
问题
bootsect、setup、head程序之间是怎么衔接的?给出代码证据。
Answer:
bootsect $\rightarrow$ setup:
| |
jmpi是过去的汇编指令,目前已经没有汇编器支持,当前能查到的手册里intel汇编指令直接使用jmp [ptr/mem]:[ins],AT&T汇编采用ljmp,对比参见此处
AT&T汇编为:
| |
setup $\rightarrow$ head:
| |
AT&T汇编为:
| |
段选择子见IA32 Manual,此处为GDT第二项
问题
- setup程序的最后是
jmpi 0,8,为什么这个8不能简单的当作阿拉伯数字8看待,究竟有什么内涵?
Answer: 见上题。
问题
- 保护模式在“保护”什么?它的“保护”体现在哪里?特权级的目的和意义是什么?分页有“保护”作用吗?
Answer: 保护模式开启:setup.s中使用
| |
保护内核/用户程序和地址空间不被其他用户程序非法执行或访问,通过硬件完成间接寻址、将虚拟地址映射到用户无法预估的物理地址、从而隐藏真实物理地址。
打开了保护模式后,CPU的寻址模式发生了变化,需要依赖于GDT去获取代码或数据段的基址。从GDT可以看出,保护模式除了段基址外,还有段限长。既有效地防止了对代码或数据段的覆盖,又防止了代码段自身的访问超限,明显增强了保护作用。
特权级的目的是限制用户对于系统关键组件的修改(例如GDTR/LDTR等),防止用户自定义数据结构覆盖内核指定的数据结构,引发非法访问的安全隐患。特权级影响范围是段,所有段选择符最后两位标识特权级。
分页也有保护作用,保证内核可以访问所有用户进程的空间,但用户进程不能够互相访问或访问内核。内核分页线性递增,能够知道虚地址实际对应的物理地址,用户程序的地址空间从高到低分配,进程的动态执行与临时分页使得页分配具有随机性,无法被预测。
问题
- 在
setup程序里曾经设置过GDT,为什么在head程序中将其废弃,又重新设置了一个?为什么设置两次,而不是一次搞好?
Answer: head中在设计缓冲区时setup设置的GDT将被覆盖。
因为要在setup中开启保护模式,只能使用jmpi跨段跳转,所有需要提前设置好GDT,但此时GDT只是为了setup能够正确执行,所以只包含其代码段数据段的项是合理的。因为setup全局仅使用一次,因此Linux在此建立再废除、重新设置的方式是很合适的,能够充分利用内存资源。
后续head直接执行内核本身代码,防止setup设置的GDT干扰,两次GDT设置是必须的,位置移动是由于编码上setup模块单读编译,不便在head中复用setup中的标志,因此在head中重新使用标签设置GDT更加方便。
问题
- 内核的线性地址空间是如何分页的?画出从
0x000000开始的7个页(包括页目录表、页表所在页)的挂接关系图,就是页目录表的前四个页目录项、第一个页表的前7个页表项指向什么位置?给出代码证据。
Answer: 页目录表和页表放在物理地址起始位置,从最高地址空间(Linux 0.11保护模式下最大寻址地址0xffffff),按照线性递减的方式设置页表项分配内核页面,方便内核能够直接以虚地址访问物理地址。
图:
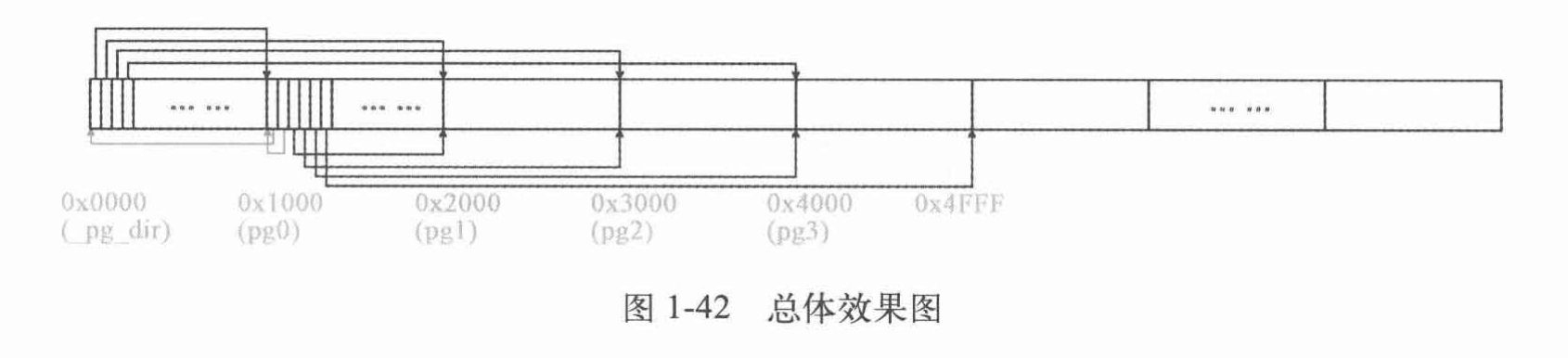
代码:
| |
cld;rep;stosl向高地址移动,将%eax值存储到%edi起始的内存位置,存储长度为%ecx,即清除内存起始的5页
使用四个页表地址设置页目录表前四项,从16MB(Linux注释误导人)页面设置页表中对应项
最后设置cr3为0x0
问题
- 根据内核分页为线性地址恒等映射的要求,推导出四个页表的映射公式,写出页表的设置代码。
Answer: Linux 0.11保护模式最高支持16MB内存,分在4个页表里,共4K页,因此以[23:22]位索引页表、以[21:12]位索引页表项(页面),以[11:0]表示页偏移找到具体的物理地址。
公式:
$$ \begin{aligned} physical\ addr & = page\ directory\ entry\ table[virtual\ addr[23:22]][virtual\ addr[21:12]] \\ & + virtual\ addr[11:0] \end{aligned} $$
代码见上题
问题
- 为什么不用
call,而是用ret“调用”main函数?画出调用路线图,给出代码证据。
Answer: call说明会返回原函数执行流,但Linux此时并不需要返回,head只进行初始化处理,操作系统是作为持续执行的程序、除非强制下电或执行关机/重启系统调用不会退出,操作系统的主循环为调度函数、处理系统调用,且是永续循环,并没有涉及退出操作,即noreturn main
因此通过模拟退栈使用ret去无返回地“调用”main是合理的
第三次作业
问题1、计算内核代码段、数据段的段基址、段限长、特权级。
Answer: GDT第二项:0x00c09a0000000fff,根据段描述符结构,[43:41]为101,即代码段,段基址0,段限长根据G(Granularity,粒度)位决定是否是字节为单位还是4KB为单位,此处G为1,因此段限长为$0x1000 \times 4KB = 16MB$,特权级为[46:45],即0
GDT第三项:0x00c0920000000fff,[43:41]为001,为数据段,数据同上
问题2、计算进程0的代码段、数据段的段基址、段限长、特权级。
Answer: 进程0 LDT位于INIT_TASK结构体:
| |
在GDT中设置LDT/TSS代码:
| |
运行中debug信息:
| |
可以印证GDT中所有项都是0特权级,表明只有内核能够访问GDT中的表项,利用GDT表项设置LDTR,而LDT中[46:45]位均为0x11即3特权级。
- 进程0代码段段基址0,段限长$0xa0 \times 4KB = 640KB$,特权级3
- 进程0数据段段基址0,段限长$640KB$,特权级3
问题3、
fork进程1之前,为什么先调用move_to_user_mode()?用的是什么方法?解释其中的道理。
Answer: 进程0和进程1怠速情况下都应该在用户态运行,与其他进程进行同样的调度,以支持系统以怠速状态运行。目前并没有引入内核进程/线程的概念,通过从用户态按照系统调用的方式调用fork操作也是更合理的操作。
| |
通过伪造中断上下文使用iret的方式硬件改变特权级,经过阅读x86 Manual,iretpop stack的顺序是eip, cs , eflags,因此在执行完iret后执行1标签后的代码,cs为0x0f,即RPL为3,则iret之后以3特权级执行代码,切换到用户态。
问题4、根据什么判定move_to_user_mode()中iret之后的代码为进程0的代码。
Answer: 根据move_to_user_mode代码:
| |
pushl $1f最终将iret后eip的值设置完成,将跳转继续执行,但是这段代码的段属性已经发生了改变,cs段pushl $0x0f已经变为3特权,ss段pushl $0x17也同样为3特权,并且他们指向的都是LDT,而且在sched_init中已经通过lldt(0)指令将LDTR指向了进程0的LDT,因此可以说此后执行的都是进程0的代码,栈也位于进程0的用户栈。
上题理解错误时以为的问题4、根据什么判定
fork之后的代码为进程0/1的代码。
Answer: 根据x86 ABI,使用%eax存储返回值,进程0 TSS中的设置为p->tss.eax = 0;,而父进程直接返回return last_pid;,_sys_fork会先调用_find_empty_process,将last_pid增加,因此父进程返回值一定为正,会与进程0区分开。
问题5、进程0的
task_struct在哪?具体内容是什么?给出代码证据。
Answer: 通过sched_init设置了进程0的TSS,具体内容:
| |
问题6、在
system.h里
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19#define _set_gate(gate_addr,type,dpl,addr) \ __asm__ ("movw %%dx,%%ax\n\t" \ "movw %0,%%dx\n\t" \ "movl %%eax,%1\n\t" \ "movl %%edx,%2" \ : \ : "i" ((short) (0x8000+(dpl%%13)+(type%%8))), \ "o" (*((char *) (gate_addr))), \ "o" (*(4+(char *) (gate_addr))), \ "d" ((char *) (addr)),"a" (0x00080000)) #define set_intr_gate(n,addr) \ _set_gate(&idt[n],14,0,addr) #define set_trap_gate(n,addr) \ _set_gate(&idt[n],15,0,addr) #define set_system_gate(n,addr) \ _set_gate(&idt[n],15,3,addr)读懂代码。这里中断门、陷阱门、系统调用都是通过
set_gate设置的,用的是同一个嵌入汇编代码,比较明显的差别是dpl一个是3,另外两个是0,这是为什么?说明理由。
Answer: 防止用户手动调用中断门、陷阱门,应该由硬件直接调用执行,而用户是必须能够访问系统调用的。
问题7、分析
get_free_page()函数的代码,叙述在主内存中获取一个空闲页的技术路线。
Answer: 使用内联汇编实现:
| |
结合二进制dump的结果:
| |
总体而言,Linux在mem_map处设置了一个bit map,用来指示内存页的空闲情况,通过检查是否存在为0的项来找到待分配的页面, 而后清空页面,将分配页面的起始地址返回,若所有页都被占用则返回0,汇编代码等价于:
| |
是否存在为0项:std ; repne ; scasb中std设置方向标志DF为1,使得指令向低地址方向移动,repne重复执行之后指令直到CX为0或标志ZF为0,scasb扫描字节,比较AL和ES:[DI]指向的内存位置的值,并且根据std减小DI。根据内联汇编参数传入,%ecx为#define PAGING_PAGES (PAGING_MEMORY >> 12)即0xf00,%edi为mem_map+PAGING_PAGES-1即0x205df,al为0。总结:从空闲内存最高位置%edi寻址第一个为0的空闲地址
rep使用%ecx标识循环次数,stosl将%eax存储到%es:edi%位置,并将%edi自增4
问题8、
copy_process函数的参数最后五项是:long eip, long cs, long eflags, long esp, long ss。查看栈结构确实有这五个参数,奇怪的是其他参数的压栈代码都能找得到,确找不到这五个参数的压栈代码,反汇编代码中也查不到,请解释原因。详细论证其他所有参数是如何传入的。
Answer: 通过反汇编查看copy_process函数中使用这些参数的代码可得:
eip:0x70(%esp)cs:0x74(%esp)eflags:0x78(%esp)esp:0x7c(%esp)ss:0x80(%esp)
系统调用内联汇编:
1 2 3__asm__ volatile ("int $0x80" : "=a" (__res) : "0" (__NR_##name));只有输入操作数能够使用数字作为constrain,表示和第index个输出操作数使用同一寄存器,因此这里输出结果和输入系统调用号都使用
%eax传递,满足x86调用约定。
根据x86手册,异常处理流程的栈安排如下:
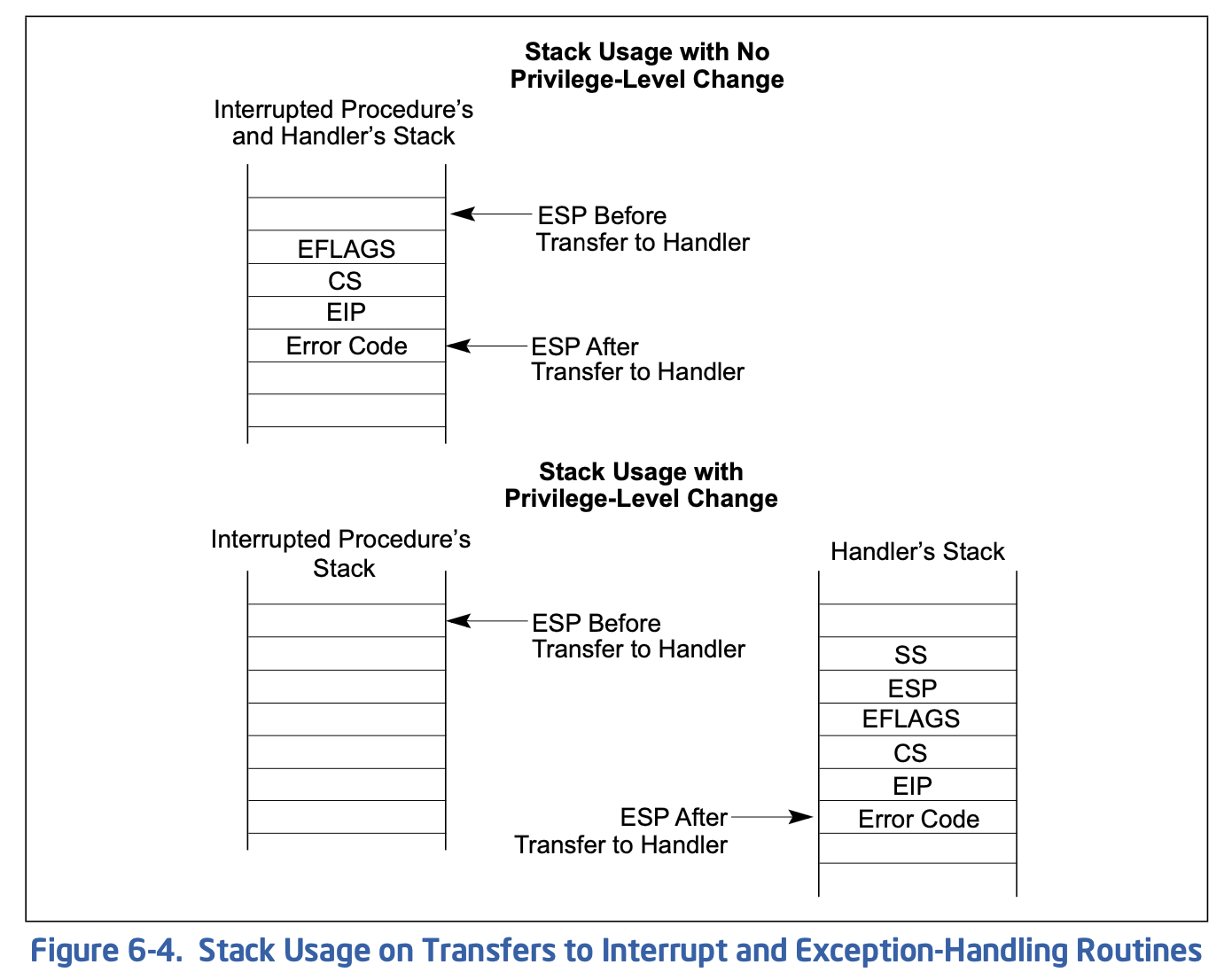
由图可见,硬件已经在陷入时帮助将必要参数压栈,而且顺序正好是五个参数对应的顺序。需要注意的是iret时必须仍然保持这个栈,以便正确返回用户态执行。
问题9、详细分析Linux操作系统如何设置保护模式的中断机制。
Answer: 首先在head.S中设置IDT,使用lidt idt_descr将256项idt数组位置等信息加载到idtr;
在trap_init设置IDT表项,即中断、系统陷入门,使得x86硬件能够正确识别并跳转对应的处理函数;
在各个处理函数正确处理栈,完成处理逻辑后使用iret返回。
问题10、分析Linux操作系统如何剥夺用户进程访问内核及其他进程的能力。
Answer: 通过分段和分页、特权级机制,特权级使得用户不可设置分段、分页相关的关键硬件,从而保障内核设置的运行机制不被破坏,分段、分页机制与特权级协同,通过权限检查使得用户只能够访问允许访问的代码段、数据段、栈段,不同段的读写执行权限限制了使用方式,每个进程的相关页面只在每个进程的页表中,由硬件支持的寻址使得每个进程只能访问分配给自己的页。
问题11、
1 2 3_system_call: cmpl $nr_system_calls-1,%eax ja bad_sys_call分析后面两行代码的意义。
Answer: 检查传入的系统调用号是否超出了支持的系统调用数量,若超出了跳转报错
第四次作业
问题1、分析
copy_page_tables()函数的代码,叙述父进程如何为子进程复制页表。
Answer: 代码如下:
| |
- 首先检查是否是4K页对齐
- 计算页目录项的内存地址,页目录项index占据虚拟地址[22]位及以上,内存地址按字节寻址,因此右移20位后清空后两位;算出页目录项所占大小
size = ((unsigned) (size+0x3fffff)) >> 22; - 按照
size页目录项循环复制页表- 检查
from/to的位置页目录表项是否Present,理应从Present向非Present设置 - 从
from的地址取出页表基址 - 为
to页表申请新页,并且设置对应页目录表项 - 注意Linux注释中指出:若
from为0,则待复制的是内核页表,只需复制160项 - Copy on Write: 将from中有效的项R/W位清空,变为只读,复制到to中
- Linux注释:内核低地址(1MB以内),不使用copy on write机制,否则需要将原先页面也改为只读,并且将
mem_map页映射记录表中该页对应项自增
- 检查
- 通过重写
cr3刷新TLB
问题2、进程0创建进程1时,为进程1建立了
task_struct及内核栈,第一个页表,分别位于物理内存两个页。请问,这两个页的位置,究竟占用的是谁的线性地址空间,内核、进程0、进程1、还是没有占用任何线性地址空间?说明理由(可以图示)并给出代码证据。
Answer: 使用内核的线性地址空间,位于函数copy_mem中,图示如下:
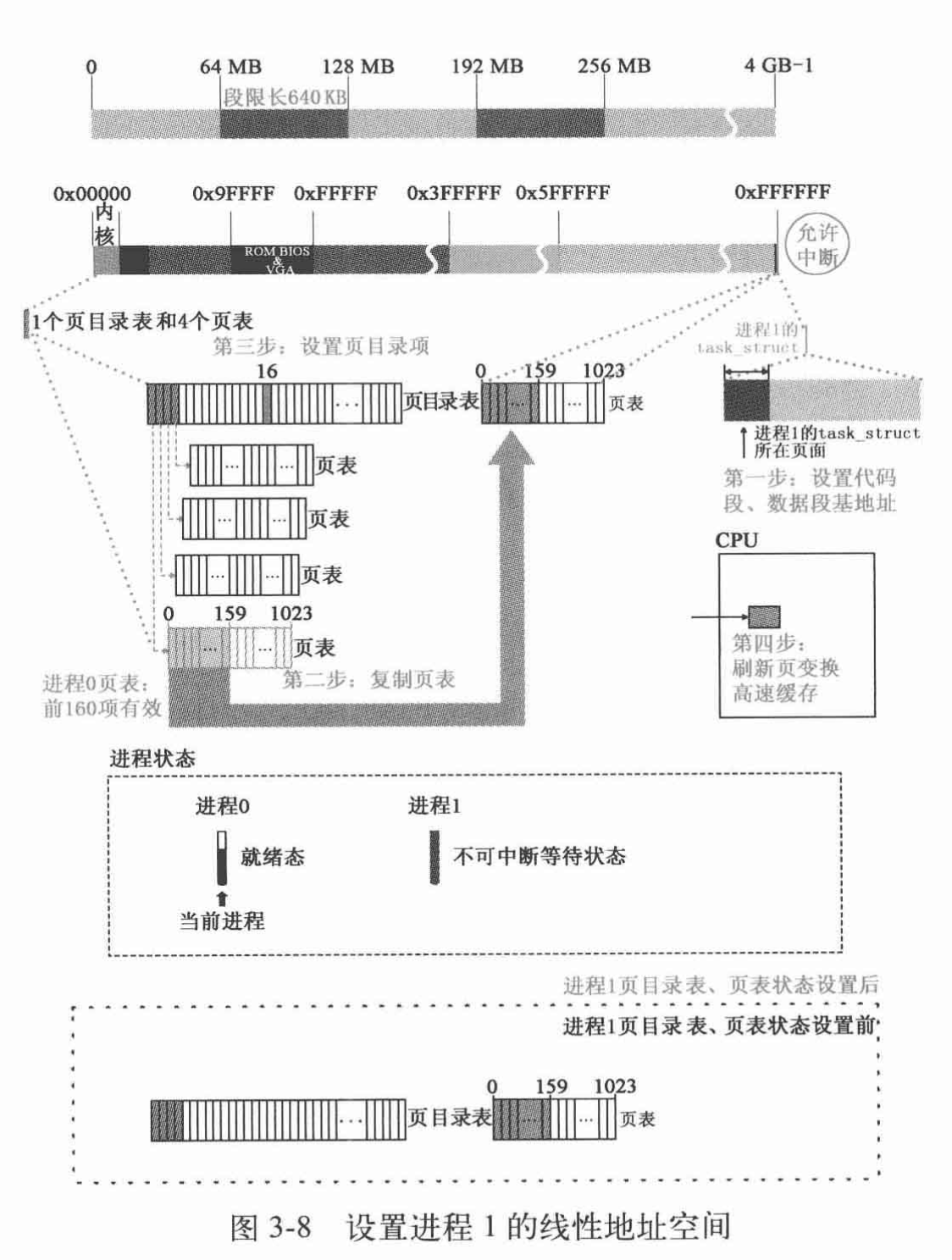
此时进程0通过fork系统调用进入内核态,内核以0特权执行代码,能够使用内核线性地址空间索引包括页表等的物理地址,内核通过get_free_page在整个线性地址空间中分配页面。进程1的页表是不能被进程1用户态访问的,一定不在进程1可访问的段和页中,不在进程1的地址空间。
由Linux分段机制,在fork操作copy_mem函数中,有如下代码:
| |
可见每64MB分段分给一个进程,不同进程所使用的页表完全隔离,进程1开始就不可能接触到起始位置为0的内存区域所在的页表,其中包括页目录表和页表。
而head.S中:
| |
表明了内核线性地址空间为内存起始16MB,为进程1分配的两个页面正好在16MB的倒数后两页,任务0线性地址空间为0~640KB,任务1线性地址空间为从64MB开始的640KB,都在这两页内存之外。
问题3、假设:经过一段时间的运行,操作系统中已经有5个进程在运行,且内核为进程4、进程5分别创建了第一个页表,这两个页表在谁的线性地址空间?用图表示这两个页表在线性地址空间和物理地址空间的映射关系。
Answer: 都在内核的线性地址空间,线性地址空间为256MB~320MB、320MB~384MB,此处只设置了两个页表,经过页目录表0x40/0x50项所引到页目录,而后根据[21:12]位索引页表,最后拼接上页内偏移即可。
问题4、
1 2 3 4 5 6 7 8 9 10 11 12 13 14#define switch_to(n) {\ struct {long a,b;} __tmp; \ __asm__("cmpl %%ecx,_current\n\t" \ "je 1f\n\t" \ "movw %%dx,%1\n\t" \ "xchgl %%ecx,_current\n\t" \ "ljmp %0\n\t" \ "cmpl %%ecx,_last_task_used_math\n\t" \ "jne 1f\n\t" \ "clts\n" \ "1:" \ ::"m" (*&__tmp.a),"m" (*&__tmp.b), \ "d" (_TSS(n)),"c" ((long) task[n])); \ }代码中的
ljmp %0\n\t很奇怪,按理说jmp指令跳转到的位置应该是一条指令的地址,可是这行代码却跳到了m (*&__tmp.a),这明明是一个数据的地址,更奇怪的,这行代码竟然能正确执行。请论述其中的道理。
Answer: 对于执行任务切换的远跳转,只有TSS选择符有用,偏移无用,对应于这里__tmp.b低2字节和__tmp.a,因此只要设置正确__tmp.b为新任务TSS选择符即可,类似[CS:EIP],以6字节作为目的地址长指针
问题5、进程0开始创建进程1,调用
fork(),跟踪代码时我们发现,fork代码执行了两次,第一次,执行fork代码后,跳过init()直接执行了for(;;) pause(),第二次执行fork代码后,执行了init()。奇怪的是,我们在代码中并没有看到向转向fork的goto语句,也没有看到循环语句,是什么原因导致fork反复执行?请说明理由(可以图示),并给出代码证据。
Answer: 内核与进程0开始分叉执行,Linux采用返回值来区分父子进程,内核先从fork系统调用返回,因为系统调用正常返回大于0的子进程id,通过if判断得到这是父进程,直接跳到for(;;) pause(),设置可中断让出cpu,而后进程0被调度,因为copy_process时将%eax设置为0:
| |
而进程0退出内核态后执行fork的下一行命令(这是int指令硬件压栈eip的结果:
| |
将返回值%eax存入栈中变量位置,因此通过if判断这是进程0在执行,进入循环体执行init()
问题6、详细分析进程调度的全过程。考虑所有可能(
signal、alarm除外)
Answer: 在就绪态进程中选择剩余时间片最多的进程调度,若都不剩余时间片,则重新分配时间片,公式:$counter = \frac{counter}{2} + priority$
问题7、分析
panic函数的源代码,根据你学过的操作系统知识,完整、准确的判断panic函数所起的作用。假如操作系统设计为支持内核进程(始终运行在0特权级的进程),你将如何改进panic函数?
Answer: 源码如下:
| |
作用:打印错误信息,陷入死循环,发生错误的进程除进程0外在循环前将缓冲区同步到磁盘。配合条件判断可以有assert类似的效果,能够很及时地发现设计问题。
由于目前只支持用户态进程,不用担心panic在陷入死循环后被打断,但是若引入内核进程,则必须在前面输出和磁盘读写完成后关中断防止被抢占,即使用cli指令
第五次作业
问题
getblk函数中,申请空闲缓冲块的标准就是b_count为0,而申请到之后,为什么在wait_on_buffer(bh)后又执行if(bh->b_count)来判断b_count是否为0?
Answer: 可能有其他任务执行到此处一起wait_on_buffer(bh),缓冲区解锁后应该重新判断,所有跳到sleep_on等待执行的程序都会被打断,其他进程可能会操作相同的内容,因此每次从sleep_on继续执行都必须检查是否接下来的动作已经被完成、该使用的组件已经被占用。后面检查是否被写(dirt位)等待同步操作后同理也需要检查缓存块是否被占用。
问题
b_dirt已经被置为1的缓冲块,同步前能够被进程继续读、写?给出代码证据。
Answer: 能够被进程继续读写,读写函数和b_dirt无关,b_dirt只决定是否需要向硬盘写回,为1意味着必须写回后才能被用作新的缓冲
只有在sys_sync, sync_dev, getblk和low level磁盘读写中会检查dirt,决定块是否能够被使用以及需要写回操作:
| |
具体读写操作主要通过bread(a)来获取缓存块,其中只会检查b_uptodate即缓冲块内容是否领先于内存,若为0需要将同步读到缓冲
| |
问题
wait_on_buffer函数中为什么不用if()而是用while()?
Answer: 函数为:
| |
循环中确保处于关中断,x86需要确保在任务切换回来的时候将中断位再次屏蔽,达到自动cli的效果
不能保证sleep_on进程被唤醒之后面对的b_lock为解锁状态,因此需要重新判断,写成repeate: if()也是可以的但是while循环更加简洁
问题
- 分析
ll_rw_block(READ,bh)读硬盘块数据到缓冲区的整个流程(包括借助中断形成的类递归),叙述这些代码实现的功能。
Answer:
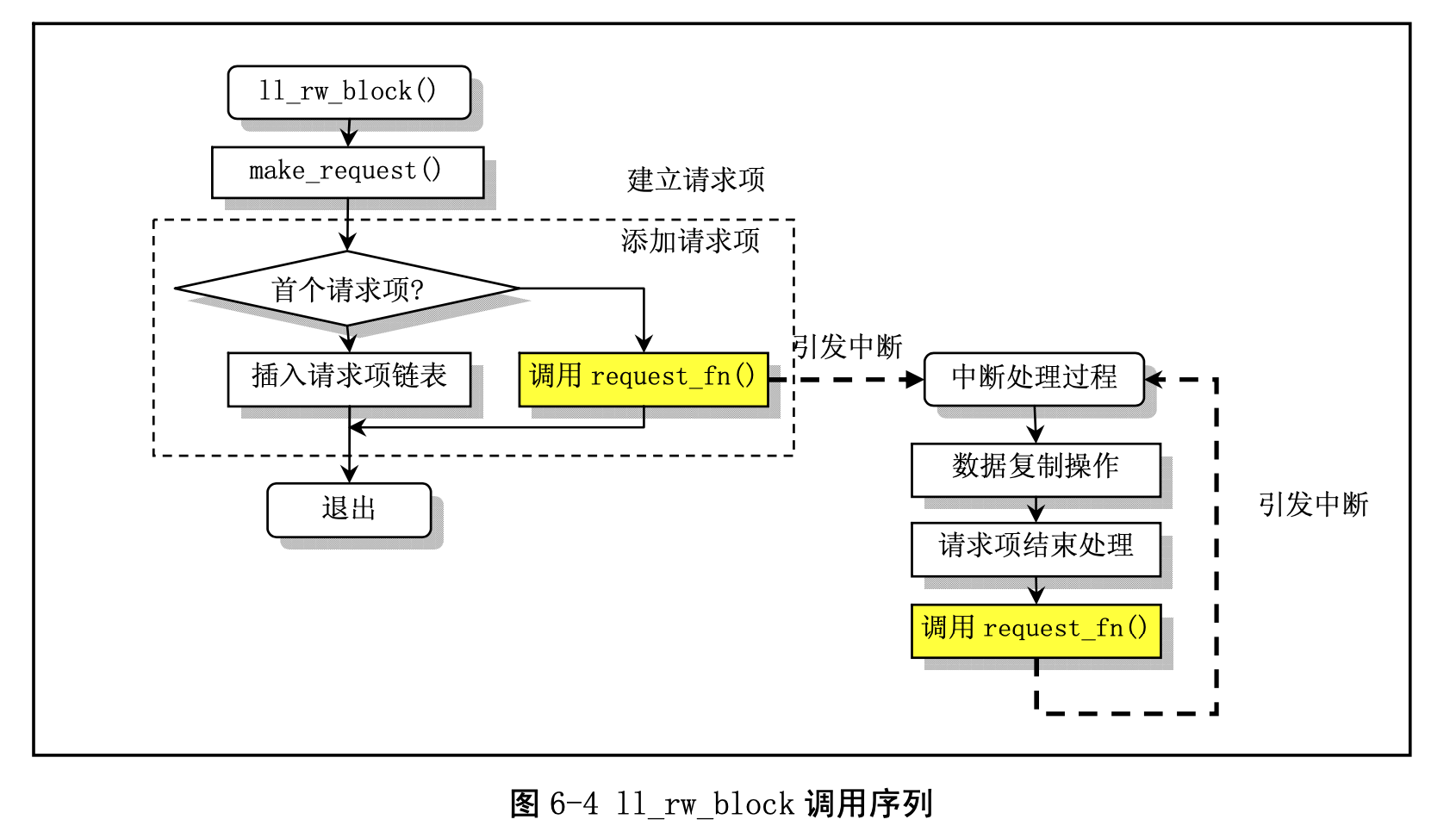
- 首先检查块设备号是否有相应设备
- 发起请求
- 将READA, WRITEA操作当成READ, WRITE处理
- 寻找到空闲的请求项,若无则等待,给读操作留更多的搜索空间
- 填入请求配置,
add_request- 设备空闲时直接调用设备
request_fn请求处理,以回调方式异步完成处理- 回调函数中包含
do_[dev]_request函数,开始新一轮的请求处理 - 无请求则返回,这时下一次
add_request将面对空闲的设备
- 回调函数中包含
- 否则,将请求放入链表等待处理
- 设备空闲时直接调用设备
首先是对于具体块设备的一层抽象:
| |
Linux-0.11实现了对三种设备的支持:软盘floppy,硬盘hd,虚拟盘ramdisk,三个请求函数分别是do_[fd/hd/rd]_request,add_request代码如下:
| |
通过dev->current_request是否为空判断具体设备是否空闲,若空闲直接调用函数处理即可,否则就将请求加入请求链表,等待处理。
下面我们来说明为什么说借助中断形成的类递归:
Linux通过两个宏定义泛化了设备中断和请求函数:
| |
我们以硬盘设备为例,另外还有一个辅助函数hd_out:
| |
在do_hd_request中根据命令的不同处理函数设置了以下几种:
| |
即在设置硬盘读写数据配置的同时将一个异常处理函数设置好,等待中断时调用,相关硬盘中断处理函数如下:
| |
注意到在do_hd_request中,每种处理函数(read_intr/write_intr/recal_intr)内部最后都调用了do_hd_request,形成递归,即处理当前请求完成后再根据请求设置设备状态、等候中断处理,完成闭环。
问题
- 分析包括安装根文件系统、安装文件系统、打开文件、读文件在内的文件操作。
Answer:
- 安装根文件系统使用
mount_root函数- 检查并初始化设备与文件系统数据结构
- 复制根设备super block(
read_super) - 读取虚拟盘中根inode放入
inode_table,并且挂接到super_block - 根文件系统与进程1关联
- 安装文件系统(
mount命令,sys_mount函数)namei,通过设备路径获取设备文件/dev/下的inode,读文件获取根设备号、读取super blocknamei,获取mnt目录onode- 将super block与根文件系统
mnt目录挂接
只有超级块挂接点的设置,但没有inode对sb的关联
| |
注意到i_mount项被置1,在iget函数中,遇到这种情况则回去超级块中寻找挂接点为该inode的项,从而实现继续索引挂接文件系统的inode寻找:
| |
- 打开文件:确定进程操作哪个文件(
sys_open)- 将用户进程
task_struct中*filep与内核file_table挂接 - 根据用户提供的路径名找到用户需要打开的文件inode(
open_namei) - inode在
file_table挂接
- 将用户进程
- 读文件(
sys_read$\rightarrow$file_read)- 调用
bmp确定文件数据块在外设上的逻辑块号 - 根据直接间接数据块找到需要读取的数据在外设的位置
bread将数据块读入缓冲块- 数据复制到进程地址空间
- 调用
问题
- 在创建进程、从硬盘加载程序、执行这个程序的过程中,
sys_fork、do_execve、do_no_page分别起了什么作用?
Answer: sys_fork从父进程分叉,执行子进程初始化,父子进程根据返回值差别判断,但都继续执行sys_fork之后的代码,do_execve加载执行可执行文件,子进程将跳转执行可执行文件,子进程并未分配执行内存空间,一旦需要写页面(数据段、栈)需要do_no_page来辅助处理缺页中断,申请内存并重新设置页表。
往年题
问题
- 一进程需要将硬盘的一个文件数据块读到缓冲区。分析这个过程并给出具体的代码证据(从
ll_rw_block函数开始分析,假设该进程已经在缓冲区中找到空闲缓冲块,并考虑多进程同时读写硬盘的情况)。
单进程情况同第五次作业题4,多进程情况事实上从getblk就已经对缓冲块设置了b_count为1,其他进程只能用相同块来索引,在make_request中使用lock_buffer来对缓冲块加锁,在buffer_head结构体中设置b_lock来辅助处理,并且在进行处理前有对b_dirt/b_uptodate的检查,若其他进程已经完成了读写任务,则直接解锁返回。加解锁代码如下:
| |
可见使用的是互斥锁(mutex)算法实现。在add_request中也使用cli/sti管理中断,防止过程被强占,保护多进程下正确性/一致性。