Megatron
参考https://www.cnblogs.com/rossiXYZ/p/15840803.html
简介
model parallelism:
- 张量并行:通信发生在每层的前向传播和后向传播过程之中,通信类型是all-reduce,不但单次通信数据量大,并且通信频繁。
- 每个transformer 层内的矩阵乘法被分割到多个GPU上
- (a) 张量并行所需的all-reduce通信需要通过服务器间的链接,这比多GPU服务器内的高带宽NVLink要慢;
- (b) 高度的模型并行会产生很多小矩阵乘法(GEMMs),这可能会降低GPU的利用率。
- 流水线并行:通信在流水线阶段相邻的切分点之上,通信类型是P2P通信,单词通信数据量较少但是比较频繁,而且因为流水线的特点,会产生GPU空闲时间,这里称为流水线气泡(Bubble)。
因为张量并行一般都在同一个机器之上,所以通过 NVLink 来进行加速,对于流水线并行,一般通过 Infiniband 交换机进行连接。
最佳micro batch size $b$取决于模型的吞吐量和内存占用特性,以及管道深度$p$、数据并行尺寸$d$和批尺寸$B$
张量模型的并行性在节点(DGX A100服务器)内是最好的,因为它会减少通信量。
尽管数据并行可以带来高效的扩展,但我们不能单独使用数据并行来处理训练批量有限的大型模型,因为a)内存容量不足,b)数据并行的扩展限制(例如,GPT-3的训练批量为1536。因此,数据并行性只支持并行到1536个GPU;然而,大约有10000个GPU用来训练这个模型)
整体流程
pretrain预训练 + finetuning微调
pretrain分为model_provider获取模型,train_valid_test_datasets_provider获取数据集,forward_step步进函数,broadcast_data广播数据,广播到所有tensor-model-parallel的其他rank上,get_tensor_model_parallel_src_rank找到TMP组源节点,作为正确的发送目的
Pretrain
- 初始化Megatron。
- 使用model_provider设置模型、优化器和lr计划。
- 调用train_val_test_data_provider以获取train/val/test数据集。
- 使用forward_step_func训练模型。
初始化Megatron
初始化全局变量
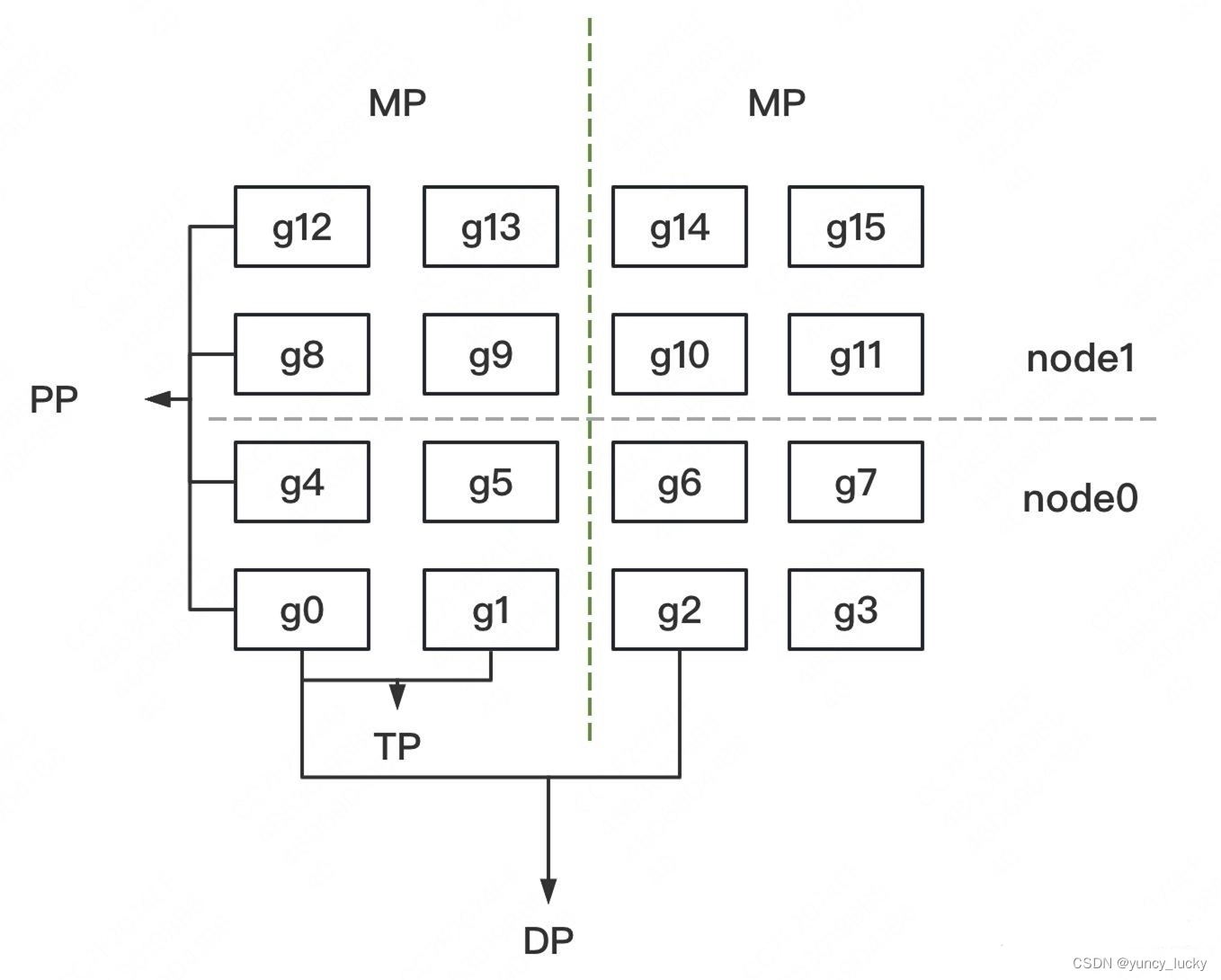
假定目前有16个GPU,属于两个node,rank 0 ~7 属于第一个节点,rank 8 ~ 15 属于第二个节点。下面的 gi 指的是第 i 个 GPU。
_TENSOR_MODEL_PARALLEL_GROUP:当前 rank 所属于的Intra-layer model parallel group,就是tensor 并行进程组。- 假如每一层分为两个tensor,则
_TENSOR_MODEL_PARALLEL_GROUP例子为:[g0, g1], [g2, g3], [g4, g5], [g6, g7], [g8, g9], [g10, g11], [g12, g13], [g14, g15]。
- 假如每一层分为两个tensor,则
_PIPELINE_MODEL_PARALLEL_GROUP:当前 rank 所属于的Intra-layer model parallel group,就是流水线进程组。- 假如流水线深度为4,则例子为 [g0, g4, g8, g12], [g1, g5, g9, g13], [g2, g6, g10, g14], [g3, g7, g11, g15]。
_MODEL_PARALLEL_GROUP:当前 rank 所属于的模型并行进程组,包括了以上两组。- 针对我们例子,就是完整模型被复制了两份,两份分别对应的 GPU 具体是[0, 1, 4, 5, 8, 9, 12, 13],[2, 3, 6, 7, 10, 11, 14, 15]
_EMBEDDING_GROUP: 嵌入对应的进程组。_DATA_PARALLEL_GROUP:当前 rank 所属于的Data parallel group。- 假如数据并行度数为2,则例子为[g0, g2], [g1, g3], [g4, g6], [g5, g7], [g8, g10], [g9, g11], [g12, g14], [g13, g15]。
- 有点疑惑
Parallel Transformer Layer
初始化
生成一个LayerNorm处理输入数据。
生成并行Attention。
生成处理attention输出的LayerNorm。
如果是decoder,则生成一个ParallelAttention。
生成一个并行MLP。
ColumnParallelLinear
RowParallelLinear
命名规范
- h: hidden size
- n: number of attention heads
- p: number of model parallel partitions
- np: n/p
- hp: h/p
- hn: h/n
- b: batch size
- s: sequence length
- l: number of layers
- Transformer 的输入size是 [s, b, h],返回一个同样size的张量,我们使用 hyperparameters 作为transformer 的超参数。
| |
PipeDream
flush三阶段:
- 预热前向传播阶段(warmup forward passes):在这里,除了最后一个stage,每个worker 会做前向计算,进行不同数目的前向传播,并且向其下游发送激活,一直到最后一个stage被激发。该计划将执行中的(in-flight)微批次数量(未完成反向传播且需要保持激活的微批次数量)限制在流水线深度之内,而不是一个批次中的微批次数量。
- 稳定 1F1B 阶段(Run 1F1B in steady state):进入稳定状态之后,每个 worker 都进行1F1B 操作。
- 冷却反向传播阶段(Cooldown backward passes):此阶段会把执行中的(in-flight)的微批次执行完毕,只是执行反向计算和向反向计算下游发送梯度。
pipeline parallelism需要inter-stage的P2P通信,其主要实现是_communnicate函数,_communicate 函数主要是封装了 PyTorch 的基础通信函数,给流水线并行提供了stage之间的双向P2P通信
稳定阶段:
- forward_step :拿到一个微批次(上游激活),进行本地前向计算。
- send_forward:
- 如果只是前向传播,则调用send_forward把本地结算结果发送给下游。
- 否则调用 send_forward_recv_backward : 本地计算结果发给下游,再从下游接受其梯度。
- 每个 worker 在 input_tensor 之中保存上游激活,在output_tensor 之中保存发送给下游的激活。
- backward_step : 本地后向计算。
- 从队列中弹出第一个未处理的(就是最早未处理的)上游激活。
- 从队列弹出对应的本地激活。
- 进行反向计算,利用(上游激活,本地激活,下游梯度)来对最早的未处理的微批次进行反向计算,得到本地梯度。
- send_backward:
- 如果是最后一个微批次,只需要把本地梯度 input_tensor_grad 传递给前向计算的上游。
- 否则调用 send_backward_recv_forward 把本地梯度 input_tensor_grad 传递给前向计算的上游,还需要从上游再获取一个激活值。
- 跳回1继续处理下一个微批次(上游激活)。